7. Image Annotation for Computer Vision#
7.1. Overview#
In this lesson, we will explore image annotation techniques and their importance in training computer vision models. We will also discuss the different types of annotations—bounding boxes, segmentation, and keypoint annotation—and how they are applied in marine imagery to improve model accuracy and reliability.
7.1.1. Learning Objectives#
By the end of this section, you will:
Understand the importance of image annotation in computer vision, explaining why annotated training data is critical for models to accurately recognize and differentiate objects in imagery data, particularly in marine environments.
Differentiate between types of annotations, identifying the key differences between bounding boxes, instance segmentation, and keypoint annotations, and determining the appropriate use cases for each.
Recognize the impact of annotation quality, evaluating how poor-quality annotations (e.g., overfitting, underfitting, or misidentification) can hinder model performance, and outlining best practices for creating effective annotations.
7.2. Classes and Annotation#
When training models using imagery data, it is crucial to provide the algorithm with properly annotated training data. This allows the model to learn what to look for and where to find it within an image. Imagine, for a moment, that you are a computer tasked with identifying every rockfish in an image, but the image is completely unannotated, and you have no prior knowledge or context of what a rockfish looks like. You would likely have a (very) hard time piecing together what that request even means. In the context of computer vision, image annotation serves as a vital guide, providing the labels and boundaries necessary for the model to understand its task. Without annotations, the model would be left guessing, unable to differentiate between objects or recognize key features.
A critical part of annotation is defining classes. In computer vision, a class refers to a category or label that is assigned to a specific object or feature within an image. Classes are essential for helping the model understand what it’s looking at. Without clear class definitions, the model wouldn’t know how to distinguish between objects like a fish and a rock or identify whether a certain object should be labeled as pollution or marine life. Classes can be very specific, such as labeling an organism down to the species level, like “rockfish,” or more generalized, such as labeling a broader group like “fish” or “jelly.”
In the context of marine imagery, classes can vary widely. Sometimes, annotations are done at a species level for detailed ecological studies, while other times, they may simply label a broader morphotype like “fish” or “jelly.” Classes are not limited to biological organisms; they can also represent other features such as geological formations (“ice,” “cobble,” “vent”) or indicators of human impact, such as “plastic debris” or “fishing gear.” The way you define classes has a significant effect on how the model learns to interpret the data. For instance, a class like “plastic” might be used to train a model that detects marine pollution, while a class like “coral” would be used in studies focusing on habitat mapping.
Properly defining and annotating these classes allows the computer to understand what it is looking for during training. Without well-defined classes, the model would be unable to make the distinctions necessary to identify objects or features within the images. Image annotation refers to the process of labeling images with these classes, which helps the machine learning model recognize objects, patterns, or other relevant features. Depending on the specific task at hand, there are different types of annotations that can be applied, each serving a distinct purpose in guiding the model’s learning process. For this lesson, we will focus on the most common annotation types, as these are foundational for many computer vision tasks and essential for developing accurate and efficient models. Proper annotation not only improves the model’s ability to detect and classify objects but also ensures the quality and reliability of the outputs in real-world applications.
There are various types of annotations depending on the task, but the most common ones we’ll focus on in this lesson are:
Bounding Boxes
Segmentation
Keypoint Annotation
These annotation types are essential for different computer vision tasks, such as object detection, segmentation, and pose estimation.
7.3. Bounding Boxes#
Bounding boxes are one of the simplest and most widely used types of annotations. They involve drawing a square rectangle around an object of interest in the image and noting the pixel coordinates of each corner as well as the class it is defining.
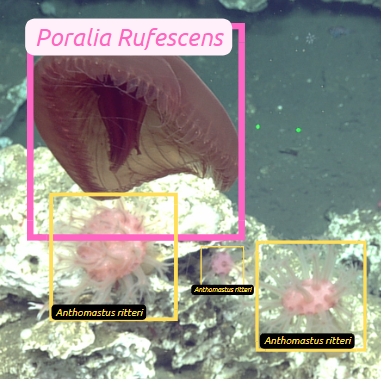
Fig. 7.1 Multiple Organisms are annotated using bounding boxes. Credit: A.Carter, OOI-NSF#
7.3.1. Format in PyTorch#
In PyTorch, the bounding box format is typically represented as [x_min, y_min, x_max, y_max], where:
x_min,y_min: Coordinates of the top-left corner of the box.x_max,y_max: Coordinates of the bottom-right corner of the box.
Example PyTorch annotation for a bounding box:
'boxes': torch.tensor([[10, 20, 200, 400], [50, 60, 220, 420]]), 'labels': torch.tensor([1, 2])
Here, two bounding boxes are defined with class labels 1 and 2 respectively.
7.4. Segmentation#
Segmentation is a more detailed annotation technique where each pixel in the object is labeled. This differs from bounding boxes, which only define the region around an object. With instance segmentation, each object instance has its own mask, allowing the model to distinguish between individual occurrences of an object within the same image. For example, if there are multiple fish in an image, instance segmentation ensures that each fish is labeled as a distinct object, even if they overlap.
In contrast, semantic segmentation assigns a label to every pixel based on the category it belongs to, without differentiating between different instances of the same object. In this case, all pixels belonging to the “fish” class, for instance, would be labeled as “fish,” but the model wouldn’t differentiate between individual fish. This approach is useful for tasks where understanding the overall composition of an image is important, such as habitat mapping or identifying general patterns in environmental features.
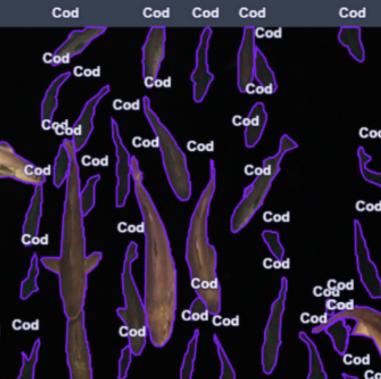
Fig. 7.2 Multiple cod are annotated using image segmentation. Credit: A.Carter, OOI-NSF#
7.4.1. Format in PyTorch#
In PyTorch, instance segmentation masks are represented as binary masks (same size as the image), where each pixel is marked as either belonging to the object (1) or the background (0).
Example PyTorch annotation for instance segmentation:
'masks': torch.tensor([[[0, 0, 0], [0, 1, 1], [0, 0, 0]], [[0, 0, 0], [0, 0, 0], [1, 1, 0]]]), 'labels': torch.tensor([1, 2])
7.5. Keypoint Annotation#
Keypoint annotation involves identifying specific points of interest on an object, like the head and tail of a fish. Each keypoint is represented by its x, y coordinates, and a visibility flag indicating if the keypoint is visible or not. This method is particularly useful in tasks like pose estimation, where the relationship between keypoints can help the model understand the orientation or movement of an object. In marine imagery, keypoint annotation can be applied to track the movement or behavior of animals by marking specific features, such as the fins of a fish or the tentacles of a jellyfish. Additionally, keypoints can be used to measure physical properties, such as the length of an organism, by placing points at key anatomical landmarks. This level of precision enables detailed analysis in both behavioral studies and environmental monitoring.

Fig. 7.3 A rockfishes length is estimated via 2 keypoint annotations. Credit: A.Carter, OOI-NSF#
7.5.1. Format in PyTorch#
In PyTorch, keypoints are represented as [x, y, visibility], where:
x,y: Coordinates of the keypoint.visibility: A flag indicating whether the keypoint is visible (1) or not visible (0).
Example PyTorch annotation for keypoint annotation:
'keypoints': torch.tensor([[[150, 200, 1], [170, 220, 1], [190, 250, 0]]]), 'labels': torch.tensor([1])
This format is commonly used in aerial surveys, where keypoints represents the head to tail length of a target animal.
7.6. PyTorch Annotation Workflow#
In a typical PyTorch workflow, annotations are stored in a dataset, where each image has a corresponding annotation that contains bounding boxes, masks, or keypoints. The dataset can then be used to train a model, such as Faster R-CNN (for object detection), Mask R-CNN (for segmentation), or HRNet (for pose estimation).
Here’s a sample structure for an annotated image in PyTorch:
'image': image, 'annotations': {'boxes': torch.tensor([[10, 20, 200, 400]]), 'labels': torch.tensor([1]), 'masks': torch.tensor([[[0, 0, 0], [0, 1, 1], [0, 0, 0]]]), 'keypoints': torch.tensor([[[150, 200, 1]]])}
By leveraging these annotations, we can effectively train models for object detection, segmentation, and pose estimation in PyTorch.
7.7. Quality of Annotations#
Not all annotations are created equal, and poor-quality annotations can significantly impact the performance and reliability of a model. Annotations produced by hasty annotators or automated processes can result in inaccuracies that may mislead the model, leading to faulty predictions or misclassifications. Incomplete, imprecise, or inconsistent labeling can introduce noise into the training data, ultimately reducing the model’s accuracy and effectiveness. These bad annotations can disrupt workflows, causing models to learn incorrect patterns, confuse similar objects, or fail to generalize well to new data. Additionally, poor annotations may lead to an increased likelihood of overfitting, where the model memorizes incorrect relationships rather than learning meaningful patterns. This can be particularly damaging when scaling the model to larger datasets or applying it to real-world scenarios.
For instance, if bounding boxes are poorly drawn—either too tightly cropped (underfitting), too loosely drawn (overfitting), or missing the object entirely— the model may struggle to focus on the object or be misled by irrelevant background. Inconsistent use of class labels across images can also confuse the model, reducing its performance. To better understand how different types of poor annotations can affect model training, the figure below demonstrates three common examples of bad bounding box annotations: overfitting, underfitting, and misidentification.

Fig. 7.4 Examples of bad bounding box annotations: overfitting, underfitting, and misidentification. Credit: A.Carter, OOI-NS#